9 Best Practices for Data Management in 2025
- Aug 13, 2025
- 15 min read
In an era where data powers every decision, managing it effectively is not just an IT task-it is the bedrock of business growth and operational efficiency. Many organizations, however, grapple with siloed information, inconsistent data quality, and cumbersome manual processes that create significant bottlenecks in their automated workflows. This inefficiency can undermine even the most sophisticated systems, from CRM platforms to complex logistics software.
This guide cuts through the noise. We will explore nine essential best practices for data management, providing concrete, actionable strategies to transform your raw information into a reliable, strategic asset. You will learn how to build a scalable and secure data foundation that supports everything from daily operations to long-term strategic planning.
From establishing a robust data governance framework and mastering your core data to implementing intelligent lifecycle management and secure archiving, these principles are designed for immediate application. Our focus is on helping you create a cohesive data ecosystem that enhances productivity, ensures compliance, and powers scalable success. By implementing these practices, you can unlock the full potential of your data, especially when integrated with powerful automation solutions that streamline workflows and drive your business forward.
1. Establish a Rock-Solid Data Governance Framework
Effective data management isn't a passive activity; it begins with a proactive, structured approach. A data governance framework is the foundational blueprint that dictates how an organization manages its data assets. This involves establishing clear policies, procedures, and accountability to ensure data is handled consistently and securely across all departments. For any business aiming to leverage automation, this framework is non-negotiable, as automated workflows are only as reliable as the data they use.
Why It's a Top Practice
A robust governance framework transforms data from a simple byproduct of operations into a strategic, high-value asset. It ensures data quality, protects against security breaches, and maintains compliance with regulations like GDPR or CCPA. For instance, General Electric implements a stringent data governance program to manage operational data from its industrial equipment, enabling predictive maintenance and optimizing performance across its vast network.
How to Implement It
Getting started with data governance can feel daunting, but a phased approach simplifies the process. Begin by identifying high-value, high-risk data domains, such as customer information or financial records.
Assign Clear Roles: Define who is responsible for specific data sets. This includes Data Owners (accountable for data in a specific domain), Data Stewards (responsible for day-to-day management), and Data Custodians (who manage the technical environment).
Involve Business Stakeholders: Data governance is not just an IT initiative. Involve leaders from marketing, sales, and operations from the outset to ensure the policies meet real-world business needs.
Leverage Technology: Use platforms like Collibra or IBM's data governance solutions to automate policy enforcement, data cataloging, and quality monitoring, which is essential for scaling your efforts.
The following diagram illustrates the core pillars of a typical data governance framework, showing how distinct components come together to form a cohesive strategy.
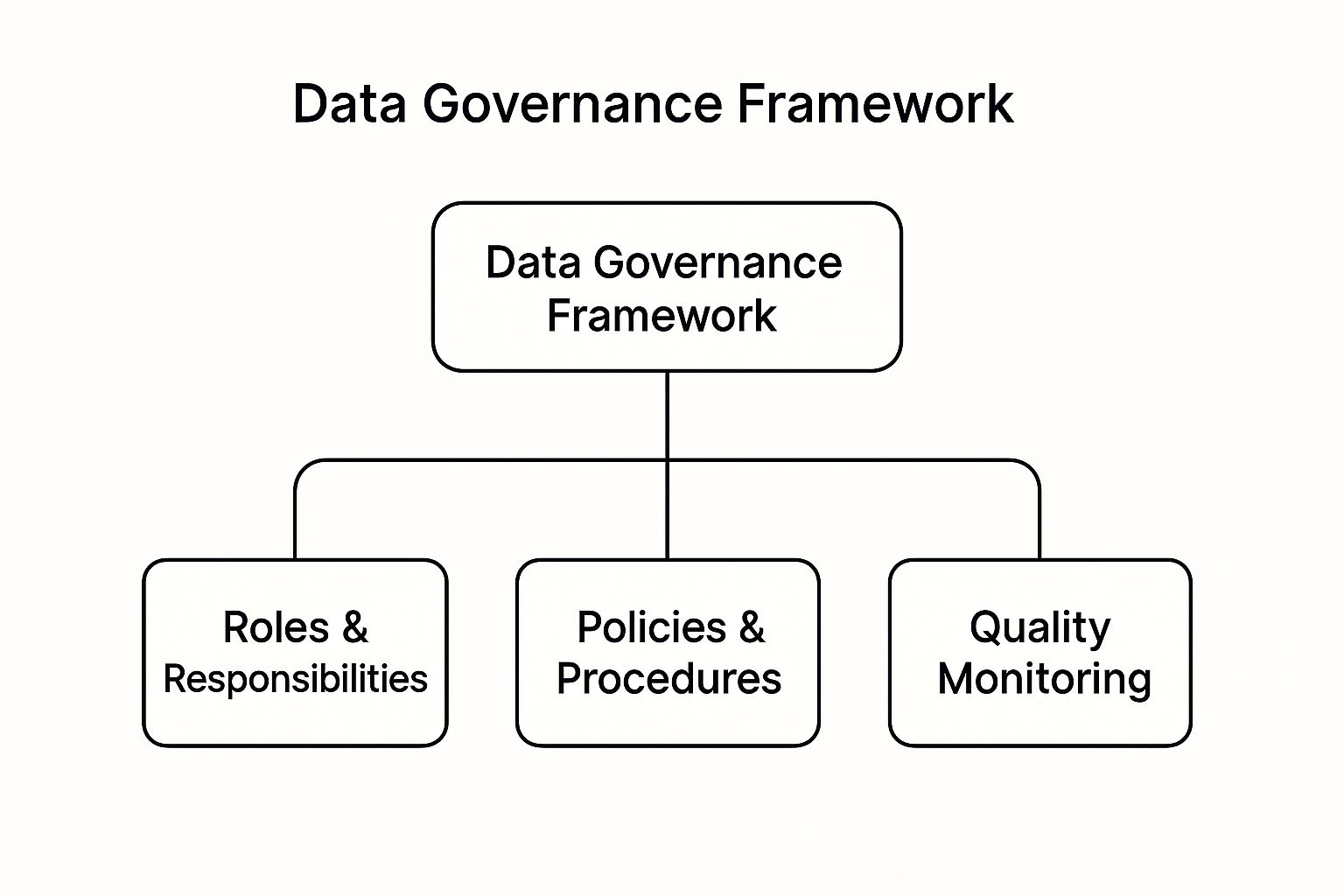
This visualization highlights that a successful framework requires a balance of human accountability (Roles), documented rules (Policies), and continuous oversight (Monitoring). By implementing these core components, you establish one of the most critical best practices for data management, creating a reliable foundation for all data-driven activities.
2. Implement Master Data Management (MDM)
While data governance sets the rules, Master Data Management (MDM) is the discipline of creating a single, authoritative source of truth for an organization's most critical data assets. MDM ensures that core business entities like customers, products, and suppliers are consistent and accurate across all systems. This unified view is fundamental for reliable automation, as it prevents discrepancies that can derail workflows, from CRM integrations to supply chain logistics.
Why It's a Top Practice
MDM directly combats data silos, where different departments hold conflicting versions of the same information. By creating a golden record, you enhance operational efficiency, improve customer experience, and enable more accurate analytics. For example, Coca-Cola manages its global customer data across over 200 markets using MDM, ensuring consistent marketing and sales strategies worldwide. This level of consistency is one of the most powerful best practices for data management you can adopt.
How to Implement It
A successful MDM initiative requires careful planning and a strategic rollout. Instead of a "big bang" approach, focus on delivering value incrementally by targeting the most impactful data domains first.
Start with One Critical Domain: Begin with a high-value, high-pain area like "customer" or "product" data. Proving the value here will build momentum and secure buy-in for future expansion.
Establish Clear Ownership: Appoint data owners and stewards specifically for master data. Their role is to define quality standards, resolve conflicts, and govern the master data lifecycle.
Choose the Right Architecture: Select an MDM architecture that fits your needs, whether it's a central repository, a registry that points to source systems, or a hybrid model.
Prioritize Change Management: MDM changes how people interact with data. Invest in training and communication to ensure user adoption and help teams understand the benefits of using the new authoritative source.
3. Prioritize Data Quality Management
High-quality data is the lifeblood of reliable automation and trustworthy business intelligence. Data quality management is the systematic process of ensuring data is accurate, complete, consistent, valid, and timely throughout its entire lifecycle. It involves a continuous cycle of monitoring, measuring, and improving data integrity to prevent flawed information from corrupting automated workflows and business decisions. Without it, you risk "garbage in, garbage out," rendering your sophisticated systems ineffective.
Why It's a Top Practice
Investing in data quality directly impacts operational efficiency, customer satisfaction, and strategic insight. High-quality data prevents costly errors, improves the accuracy of predictive models, and builds trust in your analytics. For instance, Netflix's recommendation engine relies on a rigorous data quality framework to serve personalized content, while American Express uses pristine transaction data to power its highly effective fraud detection systems. For advanced applications like AI, ensuring high data quality from the extraction phase is critical. A detailed guide on Reducing Hallucinations in AI Agents Using a Data Extraction Platform explains how foundational data integrity prevents model errors.
How to Implement It
A proactive approach to data quality management stops problems at the source rather than fixing them downstream. Start by defining what "quality" means for your key data assets.
Implement Checks at Point of Entry: Use validation rules in forms and applications to prevent incorrect data from ever entering your systems.
Establish Quality Metrics (SLAs): Define clear, measurable standards for data attributes like completeness, accuracy, and timeliness. For example, aim for 99% accuracy in all customer contact fields.
Use Automated Tools: Leverage platforms like Talend Data Quality or Informatica Data Quality to continuously monitor data streams, identify anomalies, and automate cleansing processes.
Create Feedback Loops: When errors are detected, establish a process to trace them back to their source system and correct them, training personnel on quality standards along the way. To learn more about how to get the most from your data, you can turn data into actionable insights with a practical guide.
4. Implement Robust Data Backup and Disaster Recovery
Data is vulnerable to loss from hardware failure, cyberattacks, human error, or natural disasters. A robust backup and disaster recovery (BDR) plan is a critical safety net, ensuring business continuity by allowing for rapid data restoration when disruptions occur. This strategy involves creating regular copies of data and having clear procedures to restore systems and operations, which is fundamental for any automated workflow that depends on continuous data availability.
Why It's a Top Practice
A solid BDR strategy is the ultimate insurance policy for your data assets. It minimizes downtime, prevents catastrophic data loss, and protects your organization's reputation and revenue. For example, Netflix’s cross-region data replication ensures near-constant availability, allowing the service to remain online even if an entire data center goes down. This level of resilience is a key component of modern data management best practices. For a deeper dive, this comprehensive guide to data backup offers valuable insights for UK businesses.
How to Implement It
An effective BDR plan is more than just making copies; it’s a systematic process that requires planning, testing, and documentation. Start by identifying your most critical data and systems to prioritize protection efforts.
Follow the 3-2-1 Rule: Maintain at least three copies of your data on two different types of media, with one copy stored offsite. This simple rule drastically reduces the risk of a single point of failure.
Test Recovery Procedures Regularly: A backup is useless if it can’t be restored. Routinely test your recovery process to ensure it works as expected and to identify any gaps in your plan. Documenting these procedures is also essential for efficient project management automation during a crisis.
Leverage Modern Solutions: Utilize platforms like Veeam, AWS Backup, or Commvault. These tools offer automated backup scheduling, monitoring, and simplified recovery workflows, making it easier to manage complex data environments and ensure your business can weather any storm.
5. Prioritize Data Security and Privacy Protection
In an era of constant cyber threats and stringent privacy laws, protecting data is not just an IT function; it's a core business imperative. Data security and privacy protection involve a comprehensive strategy to safeguard sensitive information from unauthorized access, breaches, and misuse. This means implementing robust technical controls and embedding privacy-by-design principles throughout the entire data lifecycle, from collection to disposal. For automated systems that handle vast amounts of data, this practice is crucial for maintaining customer trust and operational integrity.
Why It's a Top Practice
Strong data security measures are fundamental for mitigating financial and reputational risks associated with data breaches. They also ensure compliance with critical regulations like GDPR and CCPA, avoiding costly penalties. A proactive approach to security builds confidence among customers and partners, turning data protection into a competitive advantage. For example, Apple's end-to-end encryption for iCloud data and Microsoft's Azure Information Protection demonstrate how industry leaders leverage security as a brand promise, assuring users their information is handled with the utmost care.
How to Implement It
Building a resilient security posture requires a multi-layered approach that combines technology, processes, and people. Start by identifying and classifying your most sensitive data assets to apply the right level of protection.
Implement a Zero-Trust Architecture: Assume no user or device is inherently trustworthy. Verify every access request, enforce least-privilege access, and continuously monitor for suspicious activity. Solutions from providers like Palo Alto Networks or CyberArk can help enforce these principles.
Encrypt Data Everywhere: Protect data both at rest (when stored in databases or files) and in transit (as it moves across networks). This is a non-negotiable step for safeguarding sensitive customer or financial information.
Conduct Regular Security Audits: Proactively identify vulnerabilities by performing routine security assessments, penetration testing, and code reviews. This helps you address weaknesses before they can be exploited.
Train Your Team: The human element is often the weakest link. Provide regular, ongoing security awareness training for all employees to help them recognize phishing attempts, social engineering, and other common threats.
6. Implement Intelligent Data Lifecycle Management
Data doesn’t have the same value forever. Intelligent Data Lifecycle Management (DLM) is a policy-based approach to managing information throughout its entire lifespan, from creation or acquisition to archival or secure deletion. This practice ensures data is stored on the most appropriate and cost-effective infrastructure based on its current business value, access frequency, and compliance requirements. For businesses using automation, DLM is critical for maintaining system performance and managing exploding data volumes without incurring runaway costs.

Why It's a Top Practice
Effective DLM directly translates to optimized storage costs, improved application performance, and strengthened compliance. By automatically migrating aging or infrequently accessed data from expensive, high-performance storage to lower-cost tiers, organizations can significantly reduce their infrastructure budget. For example, Amazon S3’s Intelligent-Tiering automatically moves data between access tiers based on changing patterns, a system used by millions to balance cost and performance for cloud data. Similarly, NetApp's data management solutions help enterprises manage data from edge to core to cloud, automating its placement and protection.
How to Implement It
A successful DLM strategy hinges on understanding your data's value and purpose over time. This is one of the most practical best practices for data management because it yields tangible financial and operational benefits.
Classify and Value Data: Begin by categorizing your data based on its importance to business operations, its risk level, and its access frequency. Not all data is created equal, and this initial step is crucial.
Define Retention Policies: Work with legal, compliance, and business teams to establish clear rules for how long different types of data must be retained. These policies will dictate the triggers for archiving or deletion.
Automate Data Tiering: Use storage platforms like those from Dell EMC or Pure Storage that support automated tiering. Configure rules to move data from hot (frequently accessed) to warm or cold (infrequently accessed) storage based on age or access patterns.
Regularly Review Policies: Business needs and regulatory landscapes change. Schedule periodic reviews of your DLM policies to ensure they remain aligned with current requirements and continue to deliver value.
7. Data Documentation and Metadata Management
Data is useless if no one can find, understand, or trust it. Systematic data documentation and metadata management create a searchable, "living" catalog for all your data assets. This practice involves capturing and maintaining comprehensive information about your data, including its origin, structure, meaning, quality, and usage history. For automated systems that rely on precise data inputs, clear documentation is the difference between a successful workflow and a catastrophic failure.
Why It's a Top Practice
Effective documentation and metadata management democratize data access and foster a culture of trust. When users can easily discover relevant data and understand its context, they can make faster, more informed decisions. This is a cornerstone of modern best practices for data management. For example, Airbnb uses a sophisticated metadata management system to empower its teams, enabling them to explore data independently and drive product innovation without constant IT intervention. This reduces bottlenecks and accelerates data-driven decision-making.
How to Implement It
Implementing a metadata strategy requires a blend of technology and cultural change. Start by focusing on your most critical data assets to demonstrate immediate value.
Automate Metadata Capture: Manually documenting every data asset is not scalable. Use tools like Alation or Informatica Enterprise Data Catalog to automatically scan data sources, profile data, and capture technical metadata, lineage, and usage statistics.
Establish Collaborative Workflows: Documentation shouldn't be solely an IT task. Empower business users, who have the contextual knowledge, to contribute definitions, business rules, and quality ratings. This makes the documentation more relevant and accurate.
Integrate with Your Toolchain: Connect your data catalog with BI tools, development environments, and workflow platforms. This integration provides data context directly where users work, promoting adoption and ensuring consistency. To further enhance your approach, consider implementing strong knowledge management best practices to structure and share this information effectively.
8. Master Data Integration and ETL/ELT Processes
In today's fragmented technology landscape, data rarely originates from a single source. Mastering data integration is the practice of combining data from disparate systems into a unified, consistent view. This is accomplished through ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes, which systematically pull data, reshape it to fit business rules, and deliver it to a target system like a data warehouse for analysis. This is one of the most crucial best practices for data management, as it fuels reliable analytics and decision-making.
Why It's a Top Practice
Effective data integration breaks down data silos, providing a holistic view of business operations. It ensures that decision-makers are working from a single source of truth, improving the accuracy of insights and the reliability of automated workflows. For example, Netflix processes billions of events daily through a sophisticated real-time data pipeline, integrating viewing history, user interactions, and operational metrics to personalize recommendations and optimize streaming quality instantly.
How to Implement It
Building a robust integration pipeline requires a strategic approach focused on scalability and reliability. Start by identifying your key data sources and the target destination where the unified data will live.
Design for Scale: Build your ETL/ELT pipelines to handle future growth in data volume and velocity. Use tools like Apache Spark or cloud-native solutions that can scale resources on demand.
Implement Robust Monitoring: Your pipelines are critical infrastructure. Implement comprehensive monitoring and alerting to detect failures, data quality issues, or performance bottlenecks before they impact the business.
Establish Quality Checkpoints: Don't wait until data is loaded to check its quality. Build validation steps directly into your transformation logic to catch and quarantine bad data early in the process. For a deeper look into connecting disparate systems, you can learn more about systems integration and its practical applications.
By adopting these methods, you create a dependable flow of high-quality, consolidated data that can power everything from business intelligence dashboards to complex machine learning models.
9. Implement Data Archiving and Retention Policies
Not all data needs to be immediately accessible, and failing to manage its lifecycle leads to bloated, costly, and insecure systems. A strategic approach to data archiving involves systematically moving older, less frequently accessed data to long-term, cost-effective storage. This is governed by retention policies that dictate how long specific data types must be kept for legal, regulatory, or business reasons, ensuring one of the most crucial best practices for data management is met.
Why It's a Top Practice
Effective archiving and retention policies dramatically reduce primary storage costs, improve production system performance by shrinking active datasets, and ensure compliance with industry regulations. For example, financial institutions like JP Morgan must retain transactional records for seven or more years to comply with regulations. By archiving this data, they meet legal obligations without slowing down their active trading systems. Similarly, healthcare providers like Mayo Clinic archive patient records to maintain a complete history while keeping current systems lean and responsive.
How to Implement It
A successful archiving strategy balances accessibility, cost, and compliance. Start by classifying your data based on its value and the regulations it falls under.
Establish Clear Retention Schedules: Work with legal and business teams to define how long each category of data (e.g., customer PII, financial reports, operational logs) must be retained. Document these schedules clearly.
Automate Archiving Processes: Use automated workflows to identify and move data that meets the archiving criteria. This reduces manual effort and ensures policies are applied consistently.
Leverage Tiered Storage: Utilize cost-effective cloud storage solutions like AWS Glacier Deep Archive or Microsoft Azure Archive Storage. These services offer secure, low-cost storage perfect for data that is rarely accessed but must be retained.
Test Retrieval Regularly: Periodically test your ability to retrieve data from the archive to ensure it is accessible and uncorrupted when needed for an audit or legal request.
Best Practices Comparison Matrix
Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
Data Governance Framework | High – involves cross-functional coordination and ongoing updates | High – needs dedicated roles, policies, and tools | Consistent data handling, improved quality, compliance | Enterprise-wide data management, compliance focus | Ensures data quality, reduces risks, trusted data |
Master Data Management (MDM) | Very high – technical complexity and long timelines | Very high – technical expertise and infrastructure | Single source of truth, eliminates silos, regulatory support | Managing critical business entities, 360° views | Unifies data, improves accuracy, supports compliance |
Data Quality Management | Medium to high – requires ongoing monitoring and tooling | Medium – investment in tools and staff | Better decision-making, reduced bad data costs | Continuous data quality improvement | Improves accuracy, reduces costs, boosts satisfaction |
Data Backup and Disaster Recovery | Medium to high – complex infrastructure and regular testing | High – storage, replication, and testing resources | Data protection, business continuity | Protecting against loss and disasters | Ensures recovery, compliance, and peace of mind |
Data Security and Privacy Protection | High – technical complexity, regulatory demands | High – security tooling and maintenance | Data breach prevention, compliance, trust | Protecting sensitive data, regulatory adherence | Safeguards data, reduces risks, maintains reputation |
Data Lifecycle Management | Medium – requires policy design and integration across systems | Medium – tooling for automation and monitoring | Reduced costs, optimized storage, compliance | Managing data storage and retention over time | Saves costs, improves performance, automates tasks |
Data Documentation and Metadata Management | Medium to high – initially complex, requires ongoing maintenance | Medium – cataloging tools and user engagement | Improved data discovery, compliance, governance | Data cataloging and self-service analytics | Enhances findability, reduces time, supports governance |
Data Integration and ETL/ELT Processes | High – technical design, monitoring, and fault tolerance | High – skilled teams and scalable platforms | Unified data views, real-time analytics support | Combining multiple data sources for analysis | Enables comprehensive reporting, reduces silos |
Data Archiving and Retention Policies | Medium – requires policy setting and system integration | Medium – storage and maintenance costs | Cost-effective long-term data storage and compliance | Managing historical data retention and disposal | Reduces costs, ensures compliance, preserves data |
From Theory to Action: Automating Your Data Management Strategy
Navigating the landscape of data management can feel overwhelming, but as we've explored, a structured approach grounded in proven principles transforms this challenge into a significant competitive advantage. The nine pillars we've detailed, from establishing a robust Data Governance Framework to implementing meticulous Data Archiving and Retention Policies, are not isolated tasks. They are interconnected components of a single, powerful engine designed to drive your organization forward with clarity, efficiency, and security.
Implementing these concepts consistently is the critical next step. It's the difference between acknowledging a good idea and realizing its full potential. The journey begins by moving beyond manual processes, which are often the root cause of data silos, inconsistencies, and security vulnerabilities. Embracing automation is the key to embedding these best practices for data management directly into the fabric of your daily operations.
Turning Best Practices into Automated Realities
The true value of a Master Data Management (MDM) strategy or a Data Quality Management program is only fully realized when it operates continuously and seamlessly in the background. Think of it this way: a manual data backup is a single point of protection, but an automated backup schedule is a resilient, ongoing safety net. A one-time data cleanup improves a dataset, but an automated ETL process with built-in quality checks ensures that your data remains pristine and reliable day after day.
This is where the power of modern integration platforms like Zapier, Make.com, or n8n, combined with custom scripting, becomes transformative. By automating these workflows, you not only save countless hours of manual labor but also significantly reduce the risk of human error. This frees your team to focus on high-value analysis and strategic decision-making rather than getting bogged down in tedious data maintenance.
Your Actionable Path Forward
To translate this knowledge into tangible results, start with a focused assessment. Don't try to boil the ocean. Instead, identify the one or two areas from our list that represent your biggest pain points right now.
Is data inconsistency across your CRM and project management tools causing friction? Prioritize automating your Data Integration and ETL/ELT Processes.
Are you concerned about compliance and the security of sensitive client information? Focus on strengthening your Data Security and Privacy Protection protocols first.
Is your team struggling to find reliable, up-to-date information? Begin by formalizing your Data Documentation and Metadata Management.
By taking a phased, strategic approach, you build momentum and demonstrate value quickly. The ultimate goal is to create a fully integrated, automated data ecosystem where high-quality, secure, and well-documented data is not an occasional achievement but the standard. Mastering these best practices for data management is no longer just a technical imperative; it is a fundamental business strategy for sustainable growth, innovation, and operational excellence in a data-driven world.
Ready to transform your data management from a manual chore into an automated asset? The experts at Flow Genius specialize in designing and implementing custom automation solutions that embed these best practices into your core workflows using tools like Zapier, Make, and custom scripts. Schedule a consultation with Flow Genius today to build a resilient, efficient, and intelligent data ecosystem that scales with your business.

Comments