Data Integration Best Practices: Boost Your Data Strategy
- Jun 7, 2025
- 24 min read
Supercharge Your Business with Smart Data Integration
Want to streamline operations and improve decision-making? This listicle provides eight data integration best practices to help you effectively connect, transform, and leverage your data. Learn how to establish a single source of truth, implement real-time integration, ensure data quality, and design for scalability. Following these data integration best practices will unlock the potential of your data assets.
1. Establish a Single Source of Truth (SSOT)
In the realm of data integration best practices, establishing a Single Source of Truth (SSOT) stands as a foundational pillar. An SSOT is a centralized, authoritative data repository that acts as the definitive source for all critical business data. This eliminates the data silos that often plague organizations, ensuring consistency and accuracy across all departments and systems. By establishing one master version of each data element, from customer details to product information, an SSOT streamlines operations and empowers informed decision-making. Learn more about Establish a Single Source of Truth (SSOT)
Implementing an SSOT involves several key features. Centralized data governance and control ensure data quality and security. Unified data definitions and standards create a common language for data across the organization. Master data management capabilities provide tools for managing and maintaining the master data within the SSOT. Data lineage tracking allows users to understand the origin and transformation of data, enhancing transparency and accountability. Finally, conflict resolution mechanisms provide a structured approach to resolving discrepancies and maintaining data integrity.
The benefits of implementing an SSOT are substantial. Eliminating data inconsistencies and conflicts leads to improved data quality and reliability. This, in turn, enables better decision-making based on trusted data. Reduced duplicate data storage minimizes costs, while simplified compliance and audit processes streamline regulatory requirements. Examples of successful SSOT implementations include Netflix's unified customer data platform, Walmart's data lake, and Airbnb's centralized host and property database. These companies demonstrate how an SSOT can enhance operational efficiency and customer experience across diverse industries.
However, establishing an SSOT is not without its challenges. It requires a significant upfront investment in technology and resources. If not properly scaled, an SSOT can create bottlenecks in data access. Departments accustomed to controlling their own data may resist the transition. Implementation across large organizations can be complex, and the centralized nature of an SSOT introduces a risk of a single point of failure.
To mitigate these challenges, consider the following tips. Start by focusing on the most critical business entities, such as customers, products, and employees. Implement strong data governance policies before investing in technical solutions. Utilize change data capture (CDC) to keep the SSOT synchronized with source systems. Establish clear data ownership and stewardship roles to ensure accountability. Finally, adopt a gradual migration approach rather than a "big-bang" implementation to minimize disruption.
When is an SSOT the right approach? Consider implementing an SSOT if your organization struggles with data inconsistencies, spends excessive resources on data storage, or faces challenges with data-driven decision-making. If you're experiencing difficulties with compliance and audits, or if data silos are hindering collaboration and efficiency, an SSOT can provide significant benefits. This approach is particularly valuable for organizations working with large datasets, complex data integration requirements, and a need for real-time data insights.
The following infographic illustrates the core components of a Single Source of Truth. It visualizes the relationships between the SSOT itself and three crucial supporting elements: Unified Data Definitions, Master Data Management, and Data Lineage.
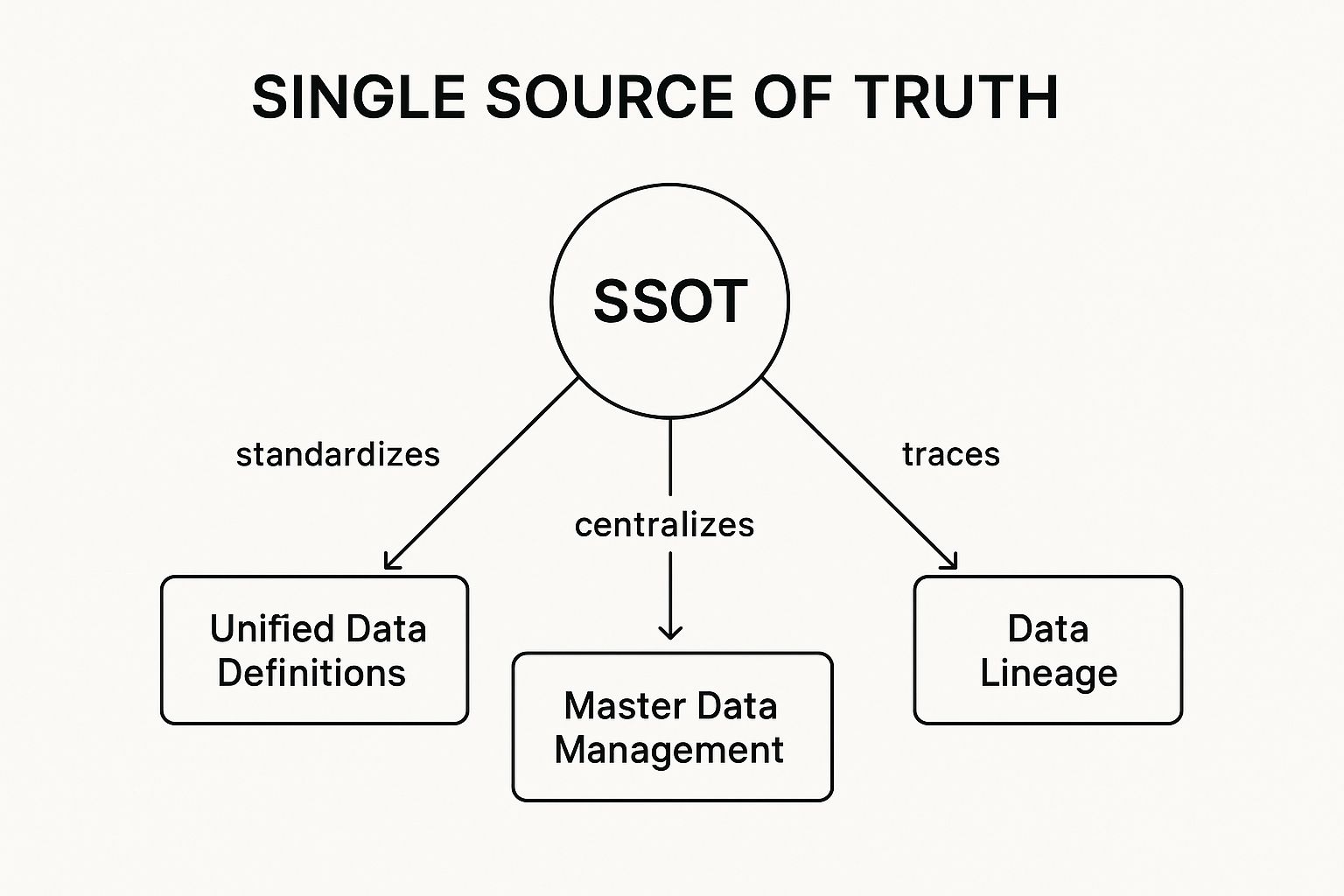
The infographic clearly demonstrates how Unified Data Definitions underpin the SSOT by providing a consistent framework for data interpretation. Master Data Management provides the tools and processes for managing the data within the SSOT, while Data Lineage offers traceability and transparency, enabling better understanding of data origins and transformations.
Implementing a robust SSOT architecture is crucial for modern organizations seeking data integration best practices. It provides a foundation for data-driven decisions, operational efficiency, and a competitive edge in today's data-centric world. The pioneers of data warehousing and dimensional modeling, like Bill Inmon and Ralph Kimball, along with research institutions such as Gartner and tech giants like Microsoft and IBM, have championed the importance of this approach. By understanding the core principles, benefits, and challenges of implementing an SSOT, organizations can embark on a successful data integration journey.
2. Implement Real-Time Data Integration
In today's fast-paced business environment, having access to up-to-the-minute data is no longer a luxury, but a necessity. This is where real-time data integration comes into play, representing a crucial data integration best practice. It enables continuous, low-latency data synchronization between different systems, empowering businesses to make informed decisions based on the most current information. This approach leverages streaming technologies and event-driven architectures to process and integrate data as it's generated, eliminating delays and ensuring that all connected systems operate with a unified, real-time view. This is essential for a wide array of applications, from real-time analytics and reporting to operational decision-making and automated responses to business events.

Real-time data integration works by capturing data at its source, the moment it's generated. This could be anything from a customer clicking a button on a website to a sensor reading on a manufacturing floor. Instead of batch processing data at intervals, real-time integration uses stream processing capabilities to handle the continuous flow of information. Event-driven architecture plays a crucial role, triggering actions based on specific events within the data stream. Low-latency data pipelines ensure that the processed data is quickly delivered to target systems, minimizing delays. This makes real-time data integration an essential best practice for organizations seeking to enhance their operational agility and responsiveness.
Examples of successful real-time data integration abound across various industries. Uber, for instance, processes over 100 billion events daily to provide real-time pricing and driver matching. PayPal uses real-time streaming for fraud detection across more than 200 markets, protecting millions of transactions every minute. Spotify streams user interaction data to provide personalized, real-time music recommendations, enhancing customer experience. Amazon leverages real-time inventory updates across its vast network of warehouses to enable same-day delivery. These examples demonstrate the transformative power of real-time data integration in optimizing operations and driving business value.
Implementing real-time data integration offers numerous advantages. It enables immediate responses to business events, empowering organizations to proactively address issues and capitalize on opportunities as they arise. It supports real-time analytics and reporting, providing valuable insights into ongoing operations and customer behavior. Real-time data integration also significantly improves customer experience by providing up-to-date information and personalized interactions. Moreover, it reduces data staleness and lag, ensuring that decisions are based on accurate and current data. Finally, real-time integration is crucial for applications like fraud detection and prevention, where immediate action is paramount.
However, adopting real-time data integration also presents some challenges. It often involves higher infrastructure and operational costs due to the need for specialized technologies and skilled personnel. The complexity of real-time systems can also be higher than traditional batch processing systems, requiring expertise in areas like stream processing, event-driven architectures, and distributed systems. Debugging and troubleshooting real-time systems can be more challenging due to the constant flow of data and the distributed nature of the architecture. Higher resource consumption, particularly in terms of processing power and network bandwidth, is also a factor to consider.
For those looking to implement real-time data integration, several best practices should be followed. Utilize reliable message streaming platforms like Apache Kafka to ensure data delivery and fault tolerance. Implement robust error handling and dead letter queues to manage failures gracefully. Monitor stream processing lag and throughput metrics to ensure optimal performance. Design for idempotency to handle duplicate messages effectively. Finally, start with high-value use cases that justify the added complexity and investment.
This approach is particularly beneficial for businesses operating in dynamic environments requiring immediate responses to changing conditions. For infrastructure project managers, this translates to synchronized logistics and communication. Technology companies benefit from integrating and automating their software ecosystems. Energy sector operations teams can optimize resource management. Logistics and supply chain directors gain seamless tracking and workflow. Even businesses like commercial cleaning companies, roofing contractors, and real estate brokers can benefit from real-time data integration to automate scheduling, supply management, and outreach. Essentially, any organization striving to automate workflows and gain a competitive edge through data-driven decision-making should consider implementing real-time data integration as a key best practice.
3. Design for Data Quality and Validation
In the realm of data integration best practices, designing for data quality and validation stands as a critical pillar for success. This involves implementing comprehensive data quality frameworks encompassing validation rules, cleansing processes, and robust monitoring mechanisms. The overarching goal is to ensure data accuracy, completeness, and consistency throughout the entire integration pipeline, from source to destination. This is paramount for any organization seeking to leverage data effectively, regardless of industry. Whether you're an infrastructure project manager coordinating logistics, a technology company integrating software ecosystems, or a real estate broker managing client data, ensuring high-quality data is fundamental to informed decision-making and efficient operations.

This approach works by proactively identifying and rectifying data issues at each stage of the integration process. Automated data profiling tools assess the incoming data, identifying potential inconsistencies, missing values, and format errors. Business rule validation engines enforce predefined rules, ensuring that data conforms to specific business requirements. Data cleansing and transformation tools then standardize data formats, correct errors, and enrich the data with additional information. Throughout this process, quality metrics and KPIs are tracked, providing continuous visibility into data quality levels. Exception handling and notification systems alert stakeholders to critical data quality issues, enabling prompt intervention and resolution.
Several organizations have demonstrated the power of robust data quality frameworks. JPMorgan Chase, for example, utilizes automated data quality checks to ensure compliance with regulatory reporting requirements. Target implements data validation to maintain product catalog accuracy across various sales channels. In healthcare, data quality frameworks are crucial for patient safety and HIPAA compliance. Even banks leverage real-time validation for Know Your Customer (KYC) processes, safeguarding against fraud and ensuring regulatory adherence. These examples highlight the broad applicability of data quality and validation across diverse industries.
Implementing effective data quality within data integration pipelines offers a plethora of benefits. It enhances the reliability of business decisions by ensuring that decisions are based on accurate and consistent data. It reduces the costs associated with poor data quality, such as rework, customer service issues, and lost revenue. High-quality data fosters increased user trust and adoption of data-driven initiatives. Moreover, it enables better regulatory compliance by ensuring that data meets required standards. Finally, it prevents downstream system failures that can arise from corrupted or inconsistent data.
While the benefits are substantial, there are some drawbacks to consider. Implementing these frameworks adds complexity to integration processes. It can potentially slow down data processing pipelines, especially during the initial implementation and validation phases. The frameworks require ongoing maintenance and updates to adapt to evolving business rules and data sources. They may occasionally reject valid but unusual data patterns, requiring manual review and adjustment. Furthermore, establishing effective validation rules often necessitates domain expertise to define proper rules and thresholds.
To successfully implement data quality and validation within your data integration initiatives, consider the following actionable tips:
Implement data quality checks at multiple pipeline stages: Don’t just rely on a single check at the end. Early and frequent validation minimizes the impact of errors.
Use statistical methods to identify anomalies and outliers: Statistical profiling can reveal hidden data quality issues that rule-based systems might miss.
Create data quality dashboards for business users: Empower business users with visibility into data quality metrics, allowing them to monitor data health and identify potential issues.
Establish data quality SLAs and metrics: Define clear service level agreements (SLAs) for data quality and track key metrics to ensure accountability and drive continuous improvement.
Implement data lineage tracking for quality issue root cause analysis: Understanding the origin and transformation of data is crucial for efficiently diagnosing and resolving data quality problems.
Learn more about Design for Data Quality and Validation and understand the crucial role it plays in addressing the evolving challenges in data integration. This proactive approach, leveraging tools from established vendors like Informatica, Talend, and IBM DataStage, is crucial for organizations striving for effective data-driven decision-making. By prioritizing data quality and validation, businesses across all sectors, from roofing contractors to logistics directors and Make.com users, can unlock the full potential of their data and pave the way for success in today's data-centric world.
4. Adopt a Microservices Architecture for Integration
In today's interconnected world, effective data integration is paramount for businesses across diverse sectors, from technology companies streamlining their software ecosystems to energy sector operations optimizing resource management. A crucial best practice for achieving seamless data integration is adopting a microservices architecture. This approach deconstructs complex data integration processes into smaller, independent services—microservices—that can be developed, deployed, and scaled individually. This modularity is key to achieving flexibility and resilience in modern data integration workflows, making it a critical component of any robust data integration strategy.
Traditional monolithic architectures often struggle to adapt to the evolving needs of modern businesses. Microservices, however, promote agility by enabling teams to work on individual services without affecting other parts of the system. This translates to faster development and deployment cycles, allowing organizations to respond more quickly to changing market demands. This architecture also enhances fault isolation. If one microservice fails, the others continue to operate, preventing a complete system outage and ensuring business continuity. This is particularly important for businesses like logistics and supply chain directors who require constant data flow for seamless tracking and workflow management.
Microservices architecture hinges on several key features. It employs a loosely coupled design, meaning services operate independently and communicate through well-defined APIs. This API-first design promotes interoperability and simplifies integration with various systems. Independent deployment and scaling is another cornerstone, allowing businesses like roofing contractors or real estate brokers to scale specific services based on demand without impacting the entire system. Features like service discovery and orchestration facilitate communication and coordination between services, while containerization support simplifies deployment and management across different environments.
The benefits of this approach are numerous. Improved scalability and performance are achieved by scaling individual services as needed. Faster development and deployment cycles empower businesses to innovate quickly and respond to market changes. Better fault isolation and resilience ensure business continuity even in the face of individual service failures. Technology diversity and flexibility allow teams to choose the best technology for each microservice. Easier maintenance and updates are facilitated by the independent nature of the services, reducing downtime and improving operational efficiency.
However, implementing a microservices architecture also presents some challenges. Increased operational complexity is inherent due to the distributed nature of the system. Network latency and communication overhead can impact performance if not carefully managed. Distributed debugging can be more challenging compared to monolithic systems. Robust monitoring and observability are crucial for managing the complex interactions between services. Finally, a microservices architecture can lead to higher infrastructure management overhead.
Despite these challenges, the benefits of microservices often outweigh the drawbacks, especially for businesses dealing with complex data integration needs. Numerous companies have successfully implemented microservices for data integration. Netflix uses microservices for content recommendation and user data integration, enabling personalized viewing experiences. Amazon’s data integration services are built on a microservices architecture, providing scalability and reliability for their vast e-commerce operations. Spotify utilizes microservices for music catalog and user preference integration, delivering seamless music streaming to millions of users. Zalando, a major European e-commerce platform, implements microservices for data integration across its operations.
For those considering implementing a microservices architecture for data integration, several tips can ensure success. Start by defining clear service boundaries based on business domains. Implement comprehensive API documentation and versioning to facilitate communication between services. Use a service mesh for secure service-to-service communication and implement circuit breakers for fault tolerance. Finally, establish clear data ownership and contracts between services to maintain data integrity and consistency. These best practices can help businesses from commercial cleaning companies automating scheduling and supply management to business brokers automating outreach leverage the power of microservices for efficient and scalable data integration.
This approach is particularly valuable for users of workflow automation platforms like Zapier, Make.com, and n8n, allowing them to create complex integrations by combining smaller, independent services. Whether you're an infrastructure project manager seeking synchronized logistics, a technology company integrating software ecosystems, or a business seeking to automate workflows, adopting a microservices architecture is a crucial data integration best practice for achieving scalability, resilience, and agility in today's dynamic business environment. The pioneers of this approach, including Martin Fowler, the Netflix Engineering Team, Amazon Web Services, the Spring Framework, and the Docker and Kubernetes communities, have demonstrated its effectiveness in handling complex, real-world integration challenges.
5. Implement Comprehensive Data Governance
Data integration, while offering immense potential, introduces complexities regarding data quality, security, and compliance. Without proper oversight, integrated data can become a liability rather than an asset. This is why implementing comprehensive data governance is crucial and earns its spot as a top data integration best practice. Data governance establishes formal policies, procedures, and organizational structures to manage data as a strategic asset throughout its entire lifecycle. It's the framework that ensures your data integration efforts remain secure, compliant, and ultimately, valuable. This best practice is essential for any organization, from infrastructure project managers seeking synchronized logistics to technology companies integrating complex software ecosystems, and even real estate brokers managing client data.
Effective data governance for data integration projects encompasses several key features:
Data Stewardship and Ownership Frameworks: Clearly define who is responsible for the quality, accuracy, and security of specific data sets within the integrated environment. This includes both source and target systems.
Policy and Procedure Documentation: Formalize rules and guidelines for data handling, access, and usage. This documentation should cover all aspects of data integration, including data transformation, validation, and error handling.
Access Control and Security Mechanisms: Implement robust security measures to protect sensitive data from unauthorized access. This includes authentication, authorization, and encryption, ensuring compliance with relevant regulations like GDPR, CCPA, and HIPAA.
Data Catalog and Metadata Management: Create a centralized repository of metadata, providing context and understanding about the integrated data. This allows users to easily discover, understand, and utilize the available data assets, fostering data discoverability and usability.
Compliance Monitoring and Auditing: Establish regular monitoring and auditing processes to ensure adherence to data governance policies and regulatory requirements. This provides a mechanism for identifying potential issues and taking corrective actions promptly.
Benefits of Implementing Data Governance in Data Integration
Implementing comprehensive data governance within a data integration project offers several significant advantages:
Ensures Regulatory Compliance and Reduces Legal Risks: By adhering to established data governance policies and procedures, organizations can minimize the risk of non-compliance with data privacy regulations, avoiding costly penalties and legal repercussions.
Improves Data Security and Privacy Protection: Robust access control mechanisms and security protocols safeguard sensitive data from unauthorized access, protecting both the organization and its stakeholders.
Increases Data Discoverability and Usability: A well-maintained data catalog with comprehensive metadata enables users to quickly locate and understand relevant data, maximizing the value of integrated data assets.
Establishes Clear Accountability for Data Quality: Defining data ownership and stewardship ensures that individuals are responsible for the quality and accuracy of specific data sets, promoting data integrity throughout the integrated environment.
Enables Better Strategic Decision-Making: By providing access to high-quality, reliable integrated data, data governance empowers organizations to make informed, data-driven decisions.
Real-World Examples of Successful Data Governance Implementation
Several organizations have successfully implemented data governance within their data integration initiatives, reaping substantial benefits. For instance, Goldman Sachs leveraged data governance to achieve regulatory compliance in its financial operations. Procter & Gamble utilizes data governance to manage vast amounts of consumer data across over 180 countries. In the healthcare sector, Kaiser Permanente established data governance for patient data integration and privacy, ensuring compliance with HIPAA. Similarly, Ford Motor Company utilizes data governance for managing the influx of data from its connected vehicles.
Actionable Tips for Implementing Data Governance
Start with High-Risk or High-Value Data Domains: Prioritize data governance implementation for areas with the highest regulatory risk or greatest business value. This allows organizations to focus resources where they are most needed.
Establish Cross-Functional Data Governance Committees: Involve representatives from different business units and IT teams in the data governance process to ensure broad buy-in and collaboration.
Implement Data Classification and Sensitivity Labeling: Categorize data based on its sensitivity and apply appropriate labels to facilitate access control and security measures.
Create Self-Service Data Catalogs for Business Users: Empower business users with intuitive data catalogs that allow them to easily discover and understand available data assets.
Regular Governance Policy Reviews and Updates: Continuously review and update data governance policies and procedures to ensure they remain relevant and effective in the face of evolving business needs and regulatory requirements.
Challenges of Data Governance
While essential, implementing comprehensive data governance isn't without challenges. It can sometimes slow down data access and innovation due to stricter controls. It requires significant organizational change and ongoing resource investment. There’s also the risk of creating bureaucratic overhead, and implementation can be especially challenging across large, complex organizations. However, the long-term benefits of robust data governance far outweigh the initial investment and effort required. By addressing these challenges proactively and focusing on a phased approach, organizations can successfully integrate comprehensive data governance into their data integration best practices and ensure the long-term value and security of their data assets. Organizations like DAMA International, MIT's Chief Data Officer program, Gartner Research, the International Association for Privacy Professionals (IAPP), and the Data Governance Institute provide further resources and best practices to help organizations navigate these complexities and successfully implement data governance frameworks.
6. Use Schema Evolution and Versioning Strategies
In the dynamic world of data integration, change is inevitable. Data structures evolve, formats shift, and new requirements emerge. Without a robust strategy to manage these changes, your meticulously crafted data pipelines can quickly become brittle, leading to integration failures, data inconsistencies, and ultimately, project delays. This is why implementing schema evolution and versioning strategies is a critical best practice for any successful data integration project. By systematically handling changes in data structures and formats, you ensure the continuous flow of information and maintain the integrity of your data ecosystem. This practice is crucial for achieving robust and adaptable data integration workflows, making it a cornerstone of data integration best practices.
Schema evolution refers to the controlled management of changes to the structure of your data, often represented in a schema. This involves mechanisms to allow for modifications to the schema over time without disrupting existing data consumers. Versioning, a core component of schema evolution, allows you to track different iterations of your schema, providing a clear history of changes and enabling compatibility between different versions. A schema registry acts as a central repository for storing and managing these schema versions, providing a single source of truth for your data structure definitions.
How it Works:
Schema evolution and versioning typically involve the following steps:
Define initial schema: Establish the initial structure of your data, specifying data types, fields, and relationships.
Register schema: Store the schema in a schema registry, assigning it a unique identifier and version number.
Implement compatibility checks: Before deploying a new schema version, perform compatibility checks against previous versions to ensure that existing consumers can still interpret the data. This involves strategies like forward compatibility (newer versions can read older data) and backward compatibility (older versions can read newer data).
Migrate data (if necessary): If the schema changes are significant, you may need to migrate existing data to conform to the new schema. Automated schema migration tools can streamline this process.
Deploy new schema: Once compatibility checks and migration are complete, deploy the new schema version to the schema registry.
Update data producers and consumers: Data producers must start using the new schema version, and consumers need to be updated to handle the changes.
Examples of Successful Implementation:
Several industry leaders have successfully implemented schema evolution and versioning to manage their complex data integration challenges. LinkedIn, for instance, leverages Avro schema evolution for their data streaming platform, enabling them to handle massive volumes of data with constantly evolving schemas. Airbnb uses schema versioning for their event tracking system, ensuring consistent and reliable data capture despite frequent changes. Shopify utilizes schema evolution to manage changes to their merchant data API, allowing them to introduce new features without disrupting existing integrations. Slack employs schema evolution and versioning to manage the intricate schema changes required for their messaging platform integrations.
Actionable Tips for Implementing Schema Evolution and Versioning:
Use schema-aware serialization formats: Leverage formats like Avro or Protocol Buffers, which are designed to support schema evolution and provide built-in compatibility checks.
Implement automated compatibility testing in CI/CD pipelines: Integrate automated testing to ensure that schema changes don't break existing integrations.
Establish clear naming conventions and deprecation policies: Consistent naming conventions and well-defined deprecation policies help manage schema evolution over time.
Maintain schema documentation and change logs: Detailed documentation and change logs provide valuable context for understanding schema evolution and troubleshooting issues.
Plan for gradual migration rather than breaking changes: Whenever possible, implement schema changes gradually to minimize disruption to existing systems.
Pros and Cons:
While schema evolution and versioning offer numerous benefits, it's important to be aware of the potential drawbacks:
Pros:
Enables continuous system evolution without downtime
Reduces integration brittleness and failures
Supports agile development practices
Minimizes coordination overhead between teams
Enables gradual rollout of schema changes
Cons:
Adds complexity to data pipeline design
Requires careful planning and testing
May lead to technical debt if not managed properly
Increased storage requirements for multiple versions
Potential performance impact from compatibility layers
When and Why to Use Schema Evolution and Versioning:
Schema evolution and versioning are particularly beneficial in scenarios where:
Data structures are expected to change frequently.
Multiple systems rely on the same data.
Maintaining backward compatibility is critical.
You need a clear history of schema changes.
You want to minimize disruption to existing integrations during schema updates.
By adopting schema evolution and versioning as a core data integration best practice, you can build robust, adaptable, and future-proof data pipelines that can gracefully handle the inevitable changes in your data landscape.
7. Implement Robust Error Handling and Recovery
In the complex world of data integration, failures are inevitable. Network hiccups, temporary service outages, data inconsistencies, and unexpected data formats can all disrupt the flow of information. To ensure your data integration processes remain reliable and resilient, implementing robust error handling and recovery is not just a best practice – it's essential. This crucial step, a cornerstone of any successful data integration strategy, allows your systems to gracefully handle failures, minimize downtime, and maintain data integrity. Ignoring error handling can lead to cascading failures, data loss, and significant manual intervention, ultimately jeopardizing your project’s success. This section explores the critical aspects of error handling and recovery, providing practical advice and examples for implementing these techniques in your data integration workflows.
Robust error handling encompasses much more than simply logging errors. It's about building comprehensive error management systems that can proactively identify, diagnose, and resolve issues, often without any human intervention. This involves several key features:
Automated Retry Mechanisms with Exponential Backoff: Transient errors, such as temporary network issues, can often be resolved by simply retrying the failed operation after a short delay. Exponential backoff enhances this by increasing the delay between retries, preventing overwhelming the failing system and giving it time to recover.
Dead Letter Queues for Failed Messages: For persistent errors that cannot be resolved through retries, dead letter queues (DLQs) provide a safe haven for failed messages. This prevents data loss and allows for later analysis and remediation of the underlying issue. Investigating messages in the DLQ can reveal systemic problems within the data integration pipeline.
Circuit Breaker Patterns for Fault Isolation: Imagine a scenario where a downstream service is experiencing prolonged downtime. Continuously retrying the operation against this failing service will not only waste resources but also potentially exacerbate the issue. The circuit breaker pattern prevents this by "tripping" after a certain number of failures, effectively isolating the failing service and preventing cascading failures throughout the system.
Comprehensive Logging and Monitoring: Detailed logs and real-time monitoring are crucial for understanding the health of your data integration processes. They provide valuable insights into error rates, latency, and other key performance indicators, allowing you to proactively identify and address potential problems.
Alerting and Notification Systems: Timely alerts notify relevant personnel when critical errors occur, enabling quick intervention and minimizing the impact of failures. These notifications can be delivered through various channels, including email, SMS, and dedicated monitoring dashboards.
Successfully implementing these features yields several significant benefits:
Improved System Reliability and Uptime: By gracefully handling errors and automatically recovering from transient issues, you significantly reduce downtime and ensure the continuous flow of data.
Reduced Manual Intervention and Operational Overhead: Automated error handling minimizes the need for manual intervention, freeing up your team to focus on more strategic tasks.
Better Visibility into System Health: Comprehensive logging and monitoring provide a clear picture of the health of your data integration processes, enabling proactive problem identification and resolution.
Enables Faster Problem Resolution: Detailed error diagnostics and alerts facilitate faster troubleshooting and resolution of issues, minimizing the impact on downstream systems.
Prevents Cascade Failures Across Systems: Mechanisms like circuit breakers isolate failing services, preventing errors from propagating throughout the system and causing widespread disruption.
While robust error handling provides numerous advantages, it’s important to be aware of the potential drawbacks:
Increased System Complexity and Resource Usage: Implementing sophisticated error handling mechanisms can add complexity to your system and require additional resources.
May Mask Underlying Problems if Not Properly Configured: Improperly configured error handling can mask underlying problems, making it harder to diagnose and resolve root causes.
Requires Careful Tuning of Retry and Timeout Parameters: Setting appropriate retry and timeout parameters is crucial for balancing resilience with efficiency.
Here are some practical tips for implementing effective error handling and recovery in your data integration best practices:
Implement Idempotent Operations: Design your data integration processes to be idempotent, meaning that executing the same operation multiple times produces the same result. This is crucial for handling duplicate processing that can arise from retries.
Use Exponential Backoff with Jitter for Retry Mechanisms: Jitter introduces a random variation to the retry interval, preventing synchronized retries that can overwhelm the failing system.
Set up Comprehensive Monitoring and Alerting for All Error Conditions: Monitor all aspects of your data integration pipeline and set up alerts for critical errors.
Create Runbooks for Common Error Scenarios: Document common error scenarios and create step-by-step instructions for resolving them.
Examples of successful implementations abound: Amazon SQS uses dead letter queues for handling failed message processing. Netflix utilizes circuit breakers to prevent cascading failures in its streaming platform. Google Cloud Dataflow and Apache Spark offer built-in retry and error handling mechanisms for data processing. These examples demonstrate the widespread adoption and effectiveness of robust error handling in real-world scenarios. By incorporating these best practices into your data integration strategy, you can ensure the reliability, resilience, and efficiency of your data pipelines. Investing in robust error handling is an investment in the long-term success of your data integration projects.
8. Design for Scalability and Performance Optimization
In the realm of data integration, scalability and performance optimization aren't just desirable features—they are essential for long-term success. As data volumes surge, user activity intensifies, and business requirements evolve, your data integration system must be capable of handling the increased load without sacrificing performance. This crucial best practice, designing for scalability and performance optimization, involves architecting your system to accommodate growth through horizontal scaling, performance tuning, and efficient resource utilization. This includes implementing strategies for data partitioning, caching mechanisms, and parallel processing techniques, ensuring your data pipeline remains robust and responsive.
Why Scalability and Performance Matter in Data Integration
A well-designed data integration system should adapt seamlessly to fluctuating demands. Imagine a rapidly growing e-commerce business. As customer orders increase, the volume of data flowing through the integration pipeline—from order placement to inventory updates to shipping notifications—explodes exponentially. A system lacking scalability would buckle under this pressure, leading to slow processing times, delayed updates, and ultimately, a compromised customer experience. Similarly, a reporting dashboard pulling data from various sources needs optimized performance to deliver real-time insights. Delays in data processing can render these insights obsolete, hindering decision-making. This is why designing for scalability and performance from the outset is critical.
Key Features and Techniques
Achieving scalability and performance requires implementing several key features:
Horizontal and Vertical Scaling: Horizontal scaling involves adding more machines to distribute the load, while vertical scaling means increasing the resources (CPU, RAM) of existing machines. Ideally, a system should leverage both approaches for optimal flexibility.
Data Partitioning and Sharding: Breaking down large datasets into smaller, manageable chunks (partitions or shards) allows for parallel processing and faster query execution. This is especially crucial for analytical workloads.
Caching Layers and Optimization: Caching frequently accessed data reduces the load on backend systems and significantly improves response times. Effective cache management is essential to ensure data consistency.
Parallel and Distributed Processing: Processing data concurrently across multiple nodes drastically reduces processing time for large datasets, enabling near real-time analytics and reporting.
Load Balancing and Resource Management: Distributing workloads evenly across available resources prevents bottlenecks and ensures consistent performance. Effective resource management optimizes utilization and minimizes costs.
Real-World Examples of Successful Implementation
Several tech giants have demonstrated the power of scalable data integration:
Facebook: Processes over 4 petabytes of data daily using distributed processing frameworks. This allows them to analyze user behavior, personalize content, and target advertising effectively.
Twitter: Handles more than 500 million tweets per day with real-time processing pipelines. This enables trending topics to surface quickly and allows for real-time monitoring of events.
Alibaba: Processes billions of transactions during Singles' Day using scalable architectures. Their system handles massive spikes in traffic without impacting performance.
Actionable Tips for Implementation
Utilize Distributed Processing Frameworks: Leverage frameworks like Apache Spark or Apache Flink for large-scale data processing.
Implement Data Partitioning: Partition data based on access patterns and business logic.
Employ Columnar Storage: Use columnar storage formats like Parquet or ORC for analytical workloads.
Optimize Resource Utilization: Implement connection pooling and resource sharing to minimize overhead.
Monitor and Optimize Queries: Regularly monitor query performance and identify areas for optimization.
Pros and Cons
Pros:
Handles growing business requirements effectively
Improves user experience with faster processing
Reduces costs through efficient resource utilization
Enables real-time processing of large datasets
Cons:
Higher initial complexity and development costs
Requires specialized expertise
Increased infrastructure costs
More complex debugging and troubleshooting
When and Why to Use This Approach
Designing for scalability and performance optimization is crucial for any data integration project expected to handle significant data volumes, high user loads, or complex processing requirements. While the initial investment may be higher, the long-term benefits in terms of performance, reliability, and cost efficiency are substantial. Neglecting this best practice can lead to performance bottlenecks, system instability, and ultimately, hinder business growth. This approach is especially vital for companies in high-growth industries, organizations dealing with real-time data streams, and businesses leveraging data analytics for strategic decision-making. By prioritizing scalability and performance, you build a future-proof data integration system ready to handle the challenges of tomorrow.
Data Integration Best Practices Comparison
Best Practice | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
Establish a Single Source of Truth (SSOT) | High - complex integration, scale | High - centralized infrastructure | Consistent, high-quality data; reduced duplication | Large enterprises needing unified data control | Eliminates inconsistencies; trusted data; simplifies audits |
Implement Real-Time Data Integration | High - advanced streaming tech | Very high - infrastructure & skills | Immediate insights; low latency data flow | Operations needing live analytics & event response | Real-time decision-making; enhances customer experience |
Design for Data Quality and Validation | Medium - additional pipeline stages | Medium - tools & maintenance | Improved data accuracy and reliability | Regulated industries; critical data accuracy | Reduces errors & failures; boosts trust & compliance |
Adopt a Microservices Architecture | High - service design & orchestration | High - operational overhead | Modular, scalable integration workflows | Complex systems needing flexibility & scalability | Fault isolation; faster deployment; tech diversity |
Implement Comprehensive Data Governance | Medium-High - organizational change | Medium - ongoing governance effort | Regulatory compliance; managed data lifecycle | Regulated and data-sensitive organizations | Clear accountability; security & privacy improvements |
Use Schema Evolution and Versioning | Medium - planning & testing | Medium - tooling and storage | Seamless schema changes without downtime | Agile environments with frequent schema updates | Reduces integration failures; supports gradual rollout |
Implement Robust Error Handling and Recovery | Medium - retry logic & monitoring | Medium - infrastructure & tuning | Increased system reliability and uptime | Distributed systems with complex workflows | Reduces manual intervention; prevents cascade failures |
Design for Scalability and Performance Optimization | High - architectural tuning | High - infrastructure & expertise | Handles large scale, high throughput loads | High volume data processing & growing user base | Faster processing; efficient resource use; supports growth |
Ready to Transform Your Data Integration Strategy?
Implementing these eight data integration best practices—establishing a single source of truth, enabling real-time data integration, prioritizing data quality and validation, adopting a microservices architecture, implementing comprehensive data governance, using schema evolution and versioning, implementing robust error handling and recovery, and designing for scalability and performance—can significantly enhance your organization's ability to harness the power of data. Whether you're an infrastructure project manager seeking synchronized logistics, a technology company automating software ecosystems, or a business broker automating outreach, mastering these data integration best practices is paramount for success. By prioritizing these core principles, you can break down data silos, overcome integration challenges, and eliminate manual processes that hinder growth. This empowers you to build a robust, scalable, and efficient data ecosystem that fuels innovation, streamlines operations, and ultimately drives informed decision-making across your organization.
Leverage the power of automation to implement these data integration best practices efficiently. Flow Genius, with its automation expertise and focus on robust and scalable integrations, can help your business establish data integration workflows that truly empower your data strategy. Visit Flow Genius today to learn more and embark on your journey towards data integration mastery.

Comments